本年もよろしくお願いします。
2024年最初の更新で真面目記事体力を使い切りそうです。
LLMを使っていろいろやる仕事に就いたことで強いGPUインスタンスを使いたいモチベが湧いたものの、EC2はTesla T4x1の構成の上はT4x4という「その間が欲しいんじゃ」という状態に。
そこで見つけたのがLambda Labs。
まだ日本語情報が多いとは言えないので使ってみた所感などをまとめてみる。
日本語情報の先達たち
Pros
- EC2などと比較して時間あたりの価格が安い
- GPU1枚、2枚、4枚、8枚の構成が選べる
Cons
Lambda Labsの概要
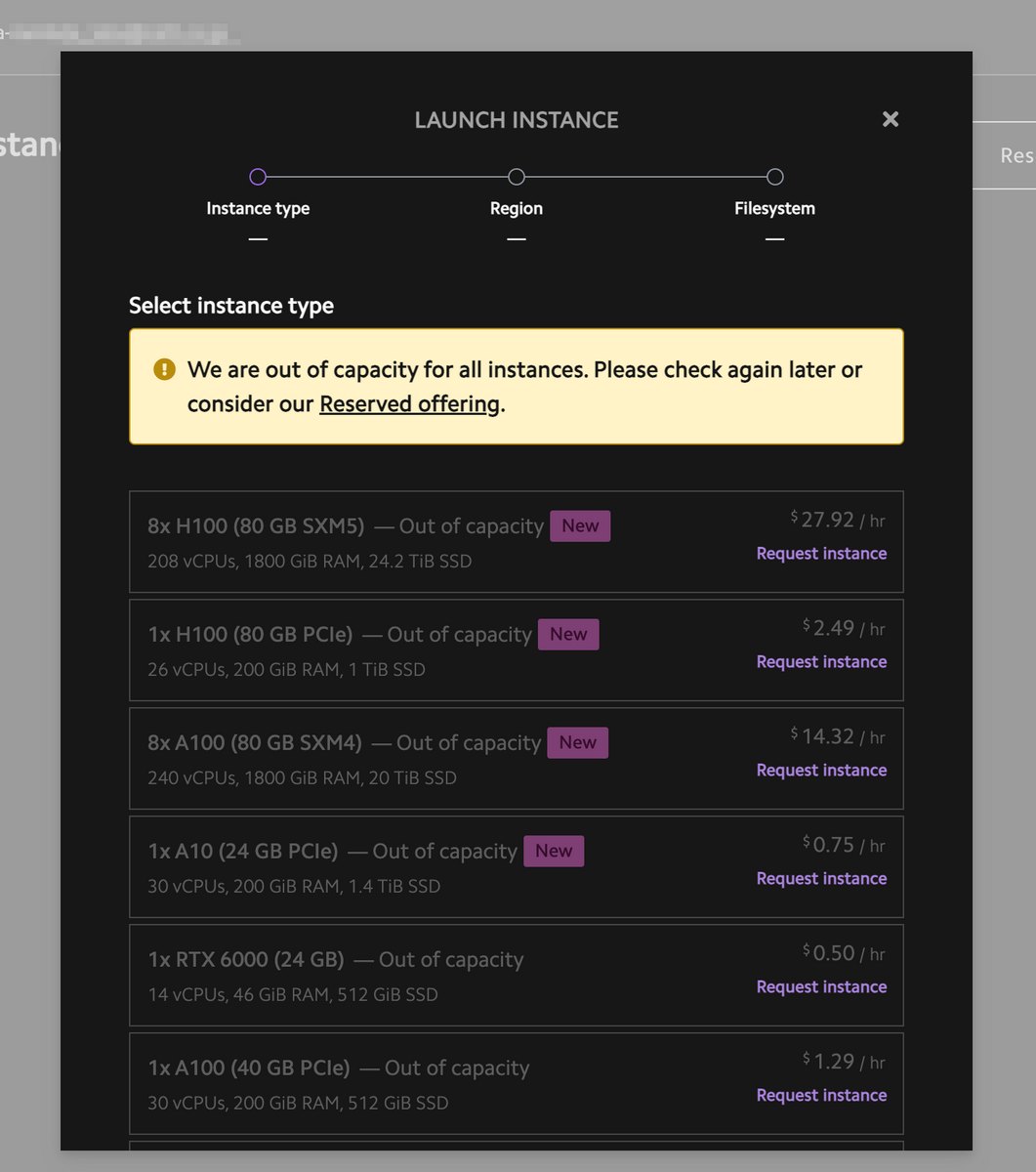
GPUの種類と価格
選べるGPUは以下の4種。
- RTX6000
- Tesla V100
- A100
- A6000
- H100
枚数によるバリエーション及び価格は以下の表の通り。
| GPU | VRAM per GPU | vCPUs | RAM | SSD | Price |
|---|---|---|---|---|---|
| 1x RTX6000 | 24GB | 14 | 46GiB | 512GiB | $0.50/hr |
| 8x Tesla V100 | 16GB | 92 | 448GiB | 5.9TiB | $4.40/hr |
| 1x A6000 | 48GB | 14 | 100GiB | 200GiB | $0.80/hr |
| 2x A6000 | 48GB | 28 | 200GiB | 1TiB | $1.60/hr |
| 4x A6000 | 48GB | 56 | 400GiB | 1TiB | $3.20/hr |
| 1x A10 | 24GB | 30 | 200GiB | 1.4Tib | $0.75/hr |
| 1x A10 PCIe | 40GB | 30 | 200GiB | 512GiB | $1.29/hr |
| 2x A10 PCIe | 40GB | 60 | 400GiB | 1TiB | $2.58/hr |
| 4x A10 PCIe | 40GB | 120 | 800GiB | 1TiB | $5.16/hr |
| 1x A100 SXM | 40GB | 30 | 200GiB | 512GiB | $1.29/hr |
| 8x A100 SXM | 40GB | 124 | 1800GiB | 6TiB | $10.32/hr |
| 8x A100 SXM4 | 80GB | 240 | 1800GiB | 20TiB | $14.32/hr |
| 1x H100 PCIe | 80GB | 26 | 200GiB | 1TiB | $2.49/hr |
| 8x H100 SXM | 80GB | 208 | 1800GiB | 26TiB | $27.92/hr |
参考. GPU Cloud - VMs for Deep Learning | Lambda (2024/01/15現在)
※ SXM: 高帯域のソケット
参考までに、Tesla T4を搭載したEC2 g4インスタンスでは、g4dn.xlarge(1x T4)が$0.71/hr, g4dn.12xlarge(4x T4)が$5.281/hrとなっている(いずれもap-northeast-1・オンデマンドの場合)。
単純比較するとLambda Labsの方が安くて大正義という感じもするが、前述の通り常にキャパ不足なので可用性においてはEC2が圧倒的に安定している。
リージョン
リージョンは北米、南米、アジア、欧州と広く用意されているがだいたい北米リージョンしか空いていない印象がある。とはいえ学習を回すだけの用途であればレイテンシは気にならないので空いているところを使えばいいと思う。
データの永続化
前述の通り、別途ストレージをインスタンスに割り当てる必要がある。これに関しては利用していないのでなんともいえない。ストレージの利用に関しては冒頭に挙げたZennの記事で解説されているのでそちらを参照ください。
学習を回してチェックポイントを保存するだけであれば、S3に入れるといった手段も取れるので工夫次第といったところか。仕事で現在動かそうとしているコードではS3に入れる方式を採っている。尚、絶賛バグ取り中なのでまだ動作確認ができていない(とあるモデルの学習の既存コードを写経・日本語向けに書き直したりしている)。
Lambda Labsを使う
ダッシュボードはこんな感じ。

最初に Settingsからカード情報を登録しておこう。
インスタンスを立ち上げる前にSSH鍵の作成or登録を忘れずに。

Launch Instance を押すとGPU選択画面が出る。GPUを選択したらリージョンとFileSystems選択をしてしばらく待てばインスタンスが立ち上がる。
SSH接続のほか、JupyterLabを使うこともできる。
ssh ubuntu@xxx.xxx.xxx -i ~/.ssh/id_rsaとか打つのが面倒なのでシェルスクリプトを書いて、ssh-lambdalabs xxx.xxx.xxxとエイリアスでsshできるようにした。
ssh ubuntu@$1 -i ~/.ssh/id_rsa
Lambda LabsでDockerを使う
dockerはインストール済みなので別途インストールの必要はなく使うことができる。そのまま使うとPermission Deniedになるのでsudoをつけているのだけども、「こうするのがベター」というのがあれば教えてください。
Dockerコンテナの中でCUDAを使う
PyTorchのイメージを使うなどいろいろあるとは思うけども、Lambda Labsが提供しているLambda StackのDockerfileがあるのでそれを使っている。
Dockerfiles with rolling-release Lambda Stack, designed for use with nvidia-container-toolkit
とあるのでこれを使っておけば良いのかなと思っている。
Dockerfile.xxxだけでなく、controlとlambda.gpgを置くのを忘れずに。
GitHubからリポジトリをcloneする
プライベートリポジトリをcloneする場合、デプロイキーの登録が必要だがインスタンスを立てるたびに色々やるのが面倒なのでローカル環境で鍵を作って、公開鍵を登録。秘密鍵はscpで送ることで解決している。これもset-lambdalabsというエイリアスにしている。setって主語がデカすぎるやろ。「こうするともっといいぞ」というのがあったら教えてください。
scp -i ~/.ssh/id_rsa ~/.ssh/lambda_labs_deploy_key ubuntu@$1:/home/ubuntu/.ssh/id_rsa
学習を実行する
ここはケースバイケースなので省略。Dockerコンテナの中で学習を回すようにしているけど、インスタンスにデフォルトでPythonだって入っているので別にコンテナでやることない気もするけど。
Lambda Labs APIを使う
Lambda Labsは起動しているインスタンスの一覧、インスタンスの起動・停止ができるAPIを提供している。
学習が終わってからもインスタンスが起動しっぱなしになってインスタンス代が無駄に嵩むのを防ぐためにも学習終了と同時に停止させられるようにしておくと良い。
起動中インスタンスのID取得とインスタンス停止のサンプルを置いておきます。
import json
import requests
LAMBDA_LABS_API_BASE = "https://cloud.lambdalabs.com/api/v1"
LAMBDA_LABS_API_KEY = "YOUR_API_KEY"
def fetch_instance_id() -> str:
endpoint = f"{LAMBDA_LABS_API_BASE}/instances"
headers = {
"Authorization": f"Bearer {LAMBDA_LABS_API_KEY}",
"Content-Type": "application/json",
}
running_instances = requests.get(endpoint, headers=headers).json()
running_instance_id = running_instances["data"][0]["id"] # インスタンスが一台だけ起動している前提
return running_instance_id
def terminate() -> None:
endpoint_terminate = f"{LAMBDA_LABS_API_BASE}/instance-operations/terminate"
headers = {
"Authorization": f"Bearer {LAMBDA_LABS_API_KEY}",
"Content-Type": "application/json",
}
running_instance_id = fetch_instance_id()
terminate_instance = json.dumps(
{
"instance_ids": [
running_instance_id,
]
}
)
requests.post(endpoint_terminate, headers=headers, data=terminate_instance)
感想
つよつよGPUを比較的安価に使えるという観点ではかなりいい選択肢だと思う。キャパ不足が目立つのがネック。
現状では学習を回す環境としての使い方がメインという印象。任意のGPUのインスタンスが安定して供給されるようになればデプロイ先としても使いたい。